Cockpit: "Dependency Analysis"
Discover non-linear dependencies between variables and analyze them in detail.
Pro This cockpit is only available in Visplore Professional.
Overview
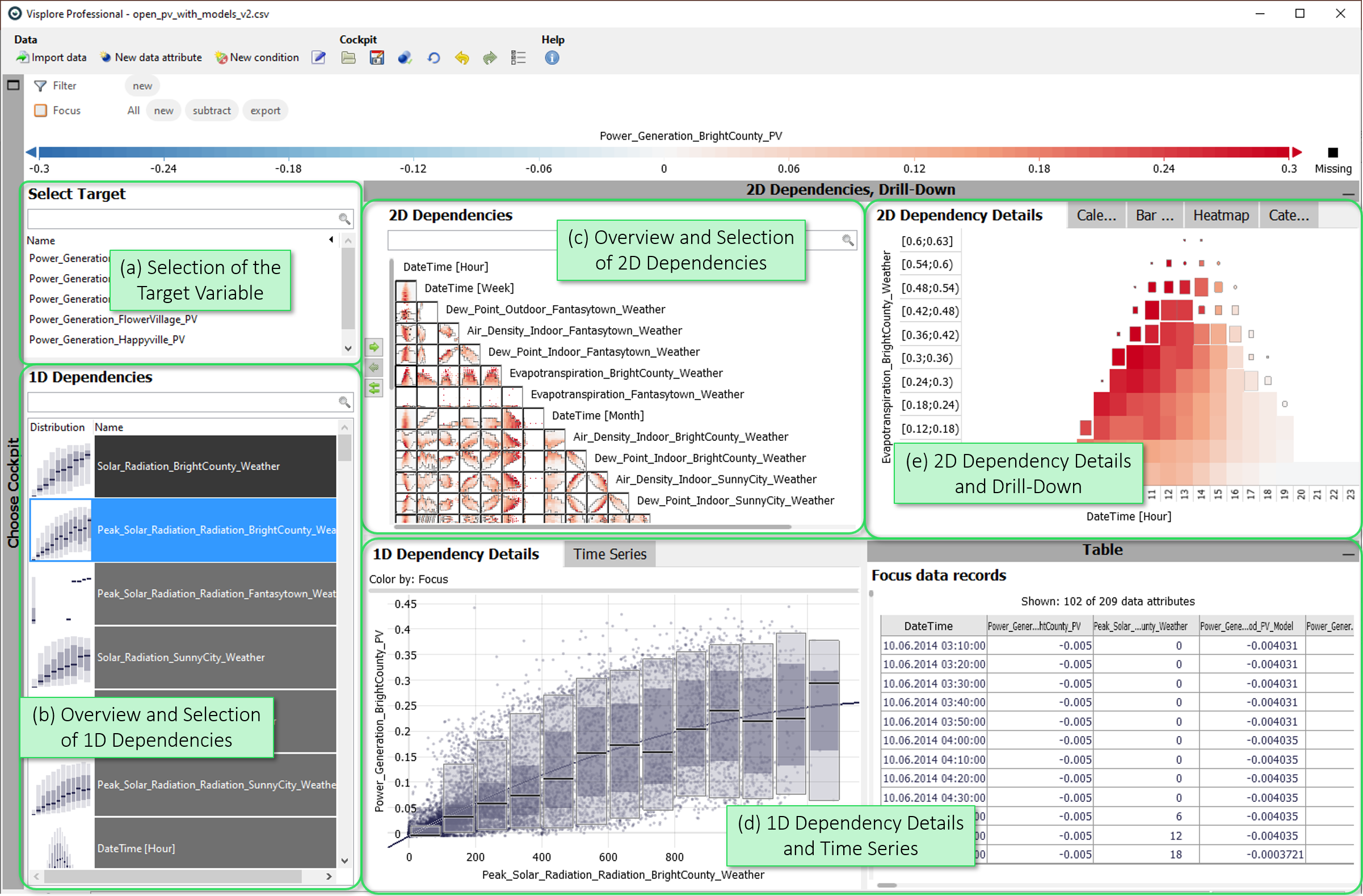
This cockpit presents the dependency of chosen target variables on other, independent variables. The goal is to identify descriptive features for modeling the targets. Dependencies on pairs of independent variables are also displayed to understand the effect of parameter interactions. If you have more than one target variable, one must be chosen for a detailed analysis at a time.
In addition to visualizations of the relationships, the dependencies are also quantified by a relevance measure, where the independent variables (or pairs) are ranked according to the strength of the relationship. Especially with larger numbers of variables, this guidance towards the most relevant ones can be very helpful.
- Selection of the Target Variable: Here, you select the currently viewed target variable by a click. If there is only one target variable, this view is not available.
- Overview and Selection of 1D Dependencies: List of independent variables ordered according to relevance for the selected target. Click the independent variable to select it for detailed visualization. Use the search field to filter the list by text in the variable name.
- Overview and Selection of 2D Dependencies: Matrix of pairs of independent variables ordered by relevance for explaining the target variable. Click to select a pair for detailed visualization.
- 1D Dependency Details and Time Series: Detailed visualization of the selected relationship. Selecting a value range for the independent variable with the left mouse button, makes the overviews visualize only the remaining target variance within the selection.
- 2D Dependency Details and Drill-Down: Detailed visualization of a selected pair of independent variables for the current target variable. Also allows data selection, such that the overviews focus on explaining the remaining variance within the selection.
Starting the cockpit: assigning semantic roles
The following roles can be given to data attibutes in this cockpit. Use the  icon in the toolbar to adjust them.
icon in the toolbar to adjust them.
- Time axis: This role can be given to a data attribute defining a temporal ordering of the data records. Can be time stamps, or values. It will be used to define the temporal context for all variables, e.g. the times of measurement, consumption, production, etc. If the role is assigned to a data attribute of date/time type, periods like 'Month', 'Hour' etc. are extracted and available for defining filters, and categorical plots like bar charts.
- Target: Variables with this role are target variables whose dependency on independent variables is to be investigated. Example: A consumption or production time series to be modeled as a function of weather time series. There must be at least one variable for this role, but there can also be more than one.
- Independent Variable: Data attributes with this role are independent variables whose influence on target variables is to be investigated. Example: Weather time series that could be relevant for a consumption or production time series. Any number of numerical and categorical variables can have this role.
- Category: Some views aggregate values by categories (e.g. per day of week, per month, etc.). When this role is assigned to a categorical data attribute, its categories are available for such aggregations. Example: Assigning this role to a 'Holiday' variable with categories 'yes' and 'no' allows comparing values like energy production for holidays vs. non-holidays. The role can also be assigned to numerical data attributes, which results in one category per distinct value of that attribute (e.g. different states encoded as 0 or 1). If the role is given to a data attribute of date/time type, periods like 'Month', 'Hour' etc. are extracted and available for defining filters, and categorical plots like bar charts.
- Upper limit (Visplore Professional only): A variable with this role defines an upper limit for another numerical variable. It is shown along with the referenced variable in time series views.
- Lower limit (Visplore Professional only): analogous to Upper limit, but for lower limits.
- Setpoint (Visplore Professional only): analogous to Upper limit, but variables with this role represent a setpoint (=desired state) for the reference variable.
Selection of the Target Variable
In this scrollable list, you can select all variables that have been assigned the "Target" role on cockpit startup.
- Click on a variable to select it.
- By entering text in the search field, you can quickly filter this list (e.g.: "Bright" -> all variables containing "Bright" in the name, such as power generation from BrightCounty).
- Search filters can also be combined by entering the binding word "or". Example: "Bright County or Fantasytown" --> All variables containing "Bright" and "Count", or "Fantasytown" are kept. Typing "not model" would remove all variables containing "model" from the list.
Overview and Selection of 1D Dependencies
This overview shows a list of all independents, sorted by their relevance for the target variable. The relevance is assessed by how much less the target varies, if the value of the independent variable is known, than when it is not known. Technically speaking, it is the R square metric of a piecewise constant model with the independent variable as input. Due to the piece-wise assessment, non-linear relationships are also found by this. The darker the background of the cell, the higher the relevance.
The second key aspect of the overview is a visualization of the dependency of the target on each independent variable. It is represented by the conditional distribution of the target variable: The independent variable is binned into discrete intervals (or categories, if categorical) along the x-axis. In each bin, the distribution of the target is shown as a vertical boxplot.
The vertical box plots per bin show the median of the target values in black and the interquartile distance in dark grey (25% to 75% percentile, i.e. the range in which the middle sorted half of the target data lies). In light grey, the range between 2.5% percentile and 97.5% percentile is displayed, i.e. the essential 95% of the data without any outliers of the target size. For a better understanding, you can click on a variable to display the plot large and labeled in the "1D Dependency Details" view.
Overview and Selection of 2D Dependencies
This overview shows a matrix of pairs of independent variables, sorted in descending order by relevance for the target variable. The relevance metric is the same as for the 1D Dependencies, however the variable pair is binned into 2D regions. Pairs with high relevance, i.e. where the target varies systematically, tend to be at the top of the matrix. Pairs of less explanatory independent variables tend to be located further down on the right.
Apart from the order, a key aspect of this overview is the visualization of the dependency of the target for each pair. In each cell of the half-matrix, the 2D space of possible values of variable pair is binned into 2D regions. In each region, the target values of points in that region is averaged, and shown in color. Thus, systematic variations are shown as color gradients in this 2D grid. For a better understanding you can click on a plot to display the plot in large and labeled in the view "2D Dependency Details".
1D Dependency Details and Time Series
This diagram shows the relationship between a target variable on the Y axis and a selected independent variable on the X axis.
If a numeric independent variable has been selected, a scatter diagram is used to display it. Additionally, the distribution of target values is summarized by box plots (based on the overview display). A regression function also provides information about a possible relationship between the two variables. If data has been selected, the box plots and the regression refer only to the selected data (focus).
2D Dependency Details and Drill-Down
This diagram serves as a detail display for the overview diagram "2D Dependencies" and shows the currently selected plot, enlarged with labels. The mean value of the target variable is color-coded using regular interval splits of the independent variables, whereby the size of the cells is scaled according to the number of averaged values.
License Statement for the Photovoltaic and Weather dataset used for Screenshots:
"Contains public sector information licensed under the Open Government Licence v3.0."
Source of Dataset (in its original form): https://data.london.gov.uk/dataset/photovoltaic--pv--solar-panel-energy-generation-data
License: UK Open Government Licence OGL 3: http://www.nationalarchives.gov.uk/doc/open-government-licence/version/3/
Dataset was modified (e.g. columns renamed) for easier communication of Visplore USPs.