Visplore – your pocket knife for CSV files
Author: Max Blöchle – November, 2022
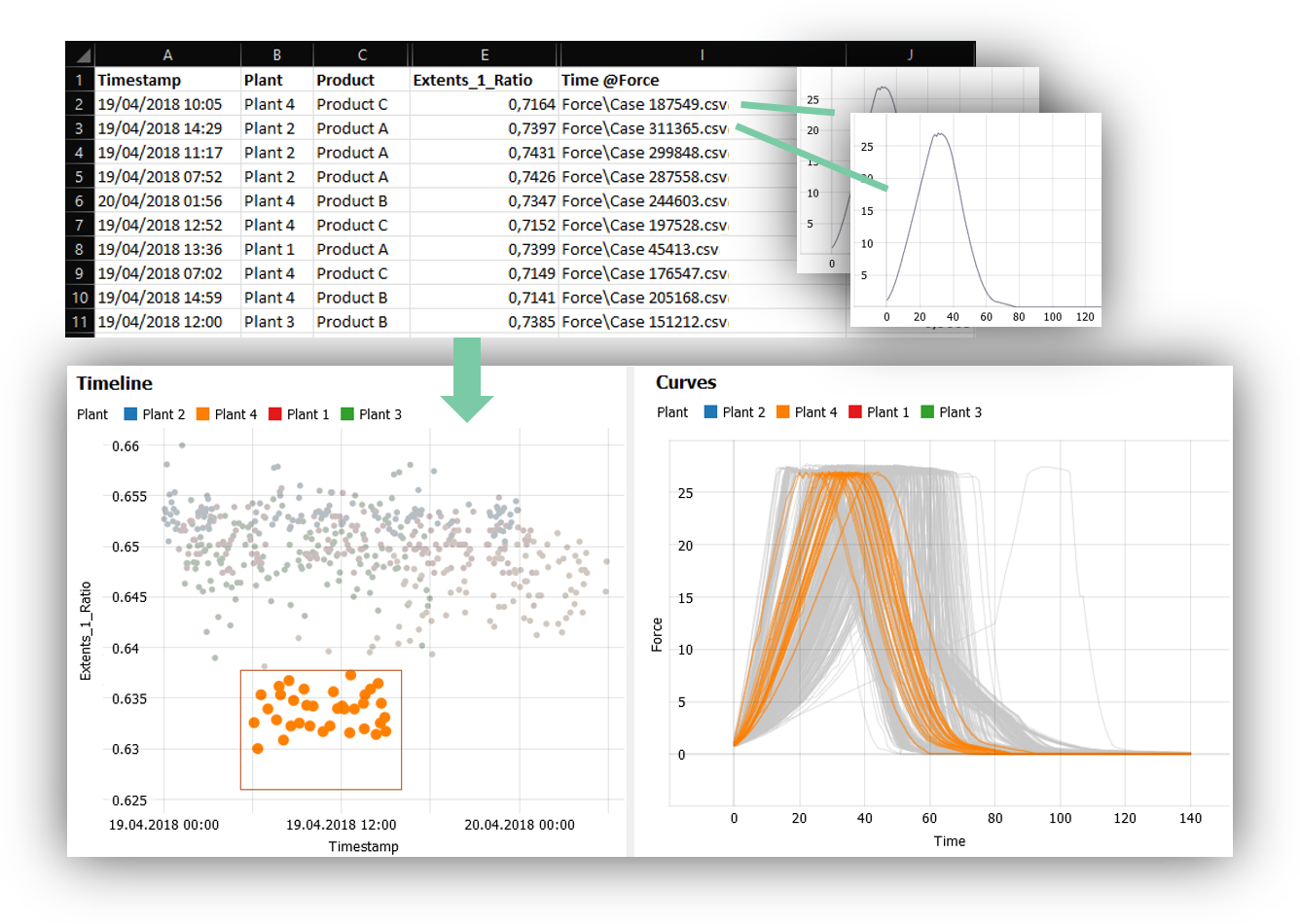
CSV files are among the most common data sources when starting a project – be it a file received from a customer, an export from an operational database, or a folder full of regularly written files from a continuous process. For all these cases, Visplore is your pocket knife to turn CSV files into valuable insights and reports within minutes!
Visplore’s CSV import functionality is among the most streamlined data connectors you will find out there: automatic detection of formats, types and comment lines, row headers from multiple lines, sampling for loading really big datasets, or just combining date and time information from separte columns – all this is easily done using an import wizard.
Today’s blog focuses on three less obvious, but often requested workflows with CSV files – hoping to bring a significant efficiency boost to your daily work!