Time Series Exploration
with Visplore
Knowing your data is the basis for efficient and successful data science.
Explore and understand massive data in minutes – interactively!


See interactive data exploration in action
Knowing your data is the basis for efficient and successful data science.
Explore and understand massive data in minutes – interactively!
See interactive data exploration in action
Don’t spend much time building and tuning charts from scratch. Visplore’s pre-configured cockpits get you way further in no time.

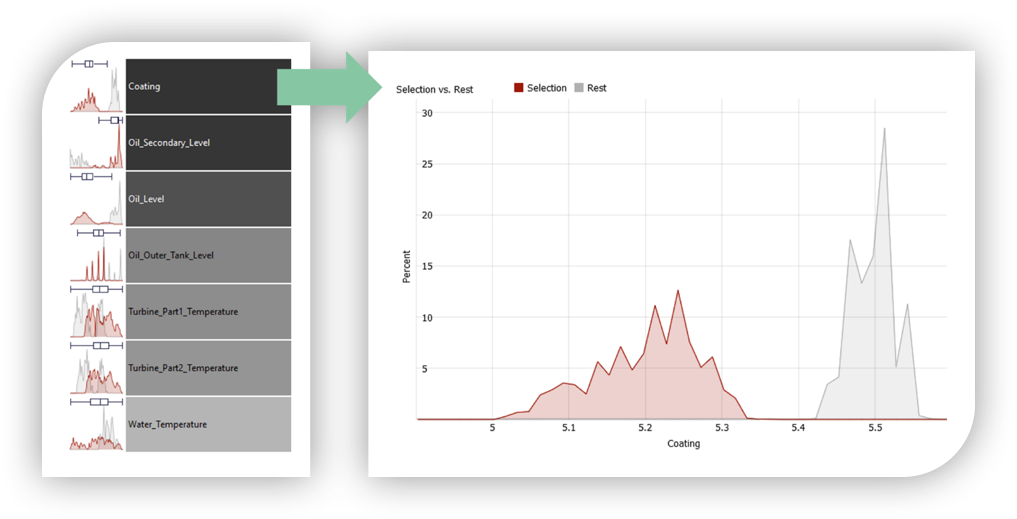
Don’t guess which variables will be relevant. Let Visplore show you. And jump seamlessly between overview and details.
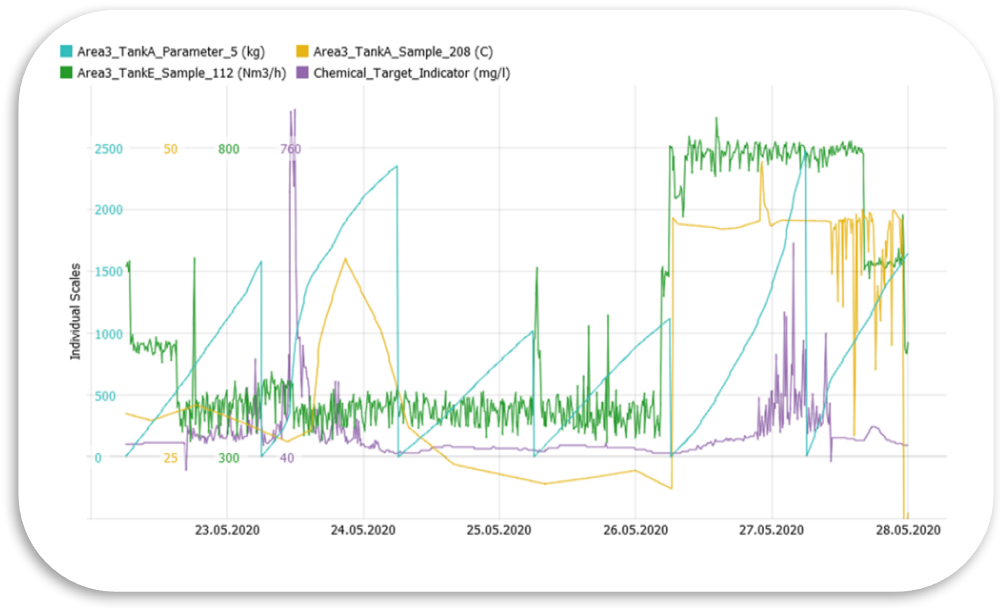
Don’t lose relevant details by pre-aggregation or filtering. Understand your data as it really is.
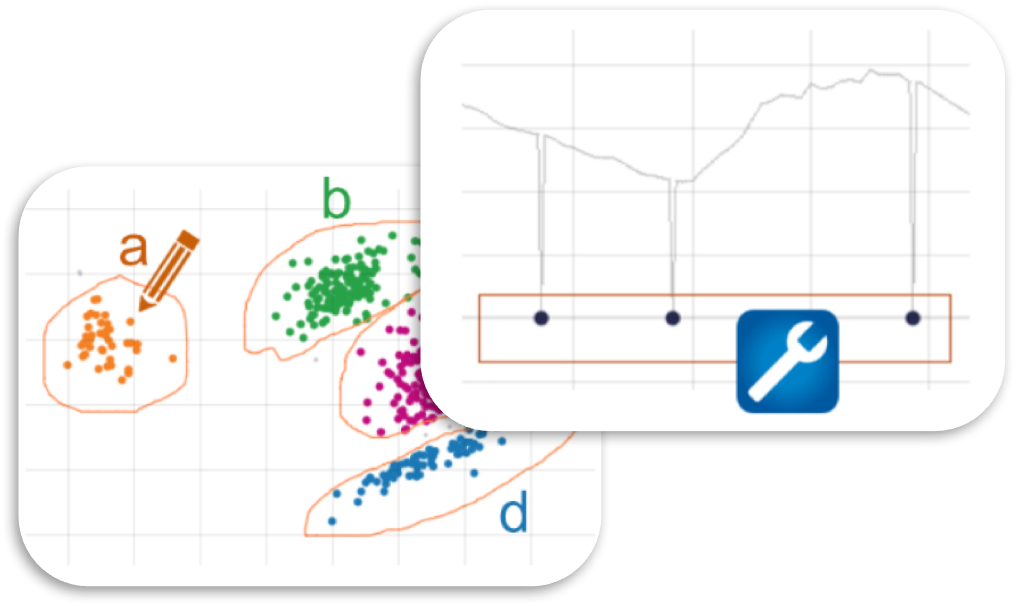
Don’t waste time for tedious cleaning of outliers, gaps, and feature engineering – do it right within the visualization and see the effect within seconds.
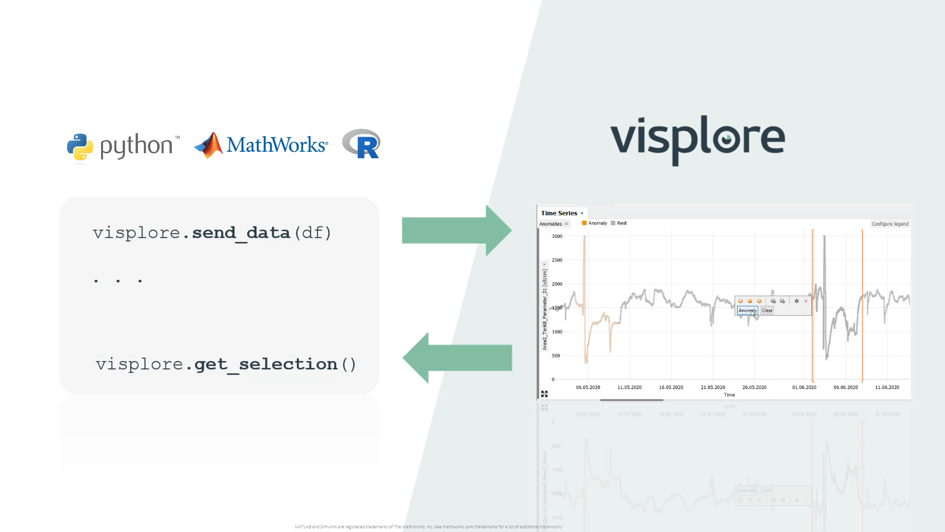
Use the right tool for each purpose. Do scripting in notebooks and data exploration in Visplore, exchanging data in both directions in just one line of code.
Data exploration is not only about discovering patterns, clusters, correlations, … It’s about understanding what all this means for your data science project. This requires domain expertise.

Traditionally, data exploration involves preparing charts and presenting them to domain experts. This often leads to more questions, requiring additional meetings and time.
It’s inefficient and can result in incomplete understanding about what’s really relevant!
Visplore answer all these ad-hoc questions on the fly, just as you sit together with the domain experts. Filtering, comparing, labeling, ranking, explaining, transforming, exporting, and way more – all it takes is a few clicks and no waiting even on massive data. The result? A more efficient workflow with a shorter data understanding phase.









